本教程将以Windows10的二进制发行版为例,通过图文形式详细介绍Stable Diffusion web UI的安装、使用技巧以及相关学习和应用资源。我们将逐步引导读者完成安装过程,并提供实用技巧以优化使用体验。同时,我们还将分享Stable Diffusion web UI的学习资源,包括官方文档、社区论坛等,帮助读者深入学习和掌握该工具。无论是初学者还是有经验的用户,都能从本教程中获得实用的指导,更加高效地使用Stable Diffusion web UI。
1.硬件配置
内存:16GB+
GPU:推荐使用NVIDIA GPU,VRAM(显存)10GB+,推荐 16GB+
CPU:i7+
2.资源和下载
官网:🔗https://ommer-lab.com/research/latent-diffusion-models/ ↗
论文:🔗https://arxiv.org/abs/2112.10752 ↗
官方库地址:🔗https://github.com/CompVis/stable-diffusion ↗
WebUI官方库地址:🔗https://github.com/AUTOMATIC1111/stable-diffusion-webui ↗
WebUI的Windows10二进制发行版:🔗https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/download/v1.0.0-pre/sd.webui.zip ↗
网盘地址:🔗https://pan.baidu.com/s/1ngbtJCWsDRb7GPjkcofjYQ?pwd=34kk ↗
3.运行
解压文件到目录
第一次运行,先运行update.bat;
更新完毕按任意键退出更新脚本;
然后再运行run.bat;第一次运行会自动所需文件,视网络情况,时间会久一些,如果中断就关闭命令窗口重新执行;
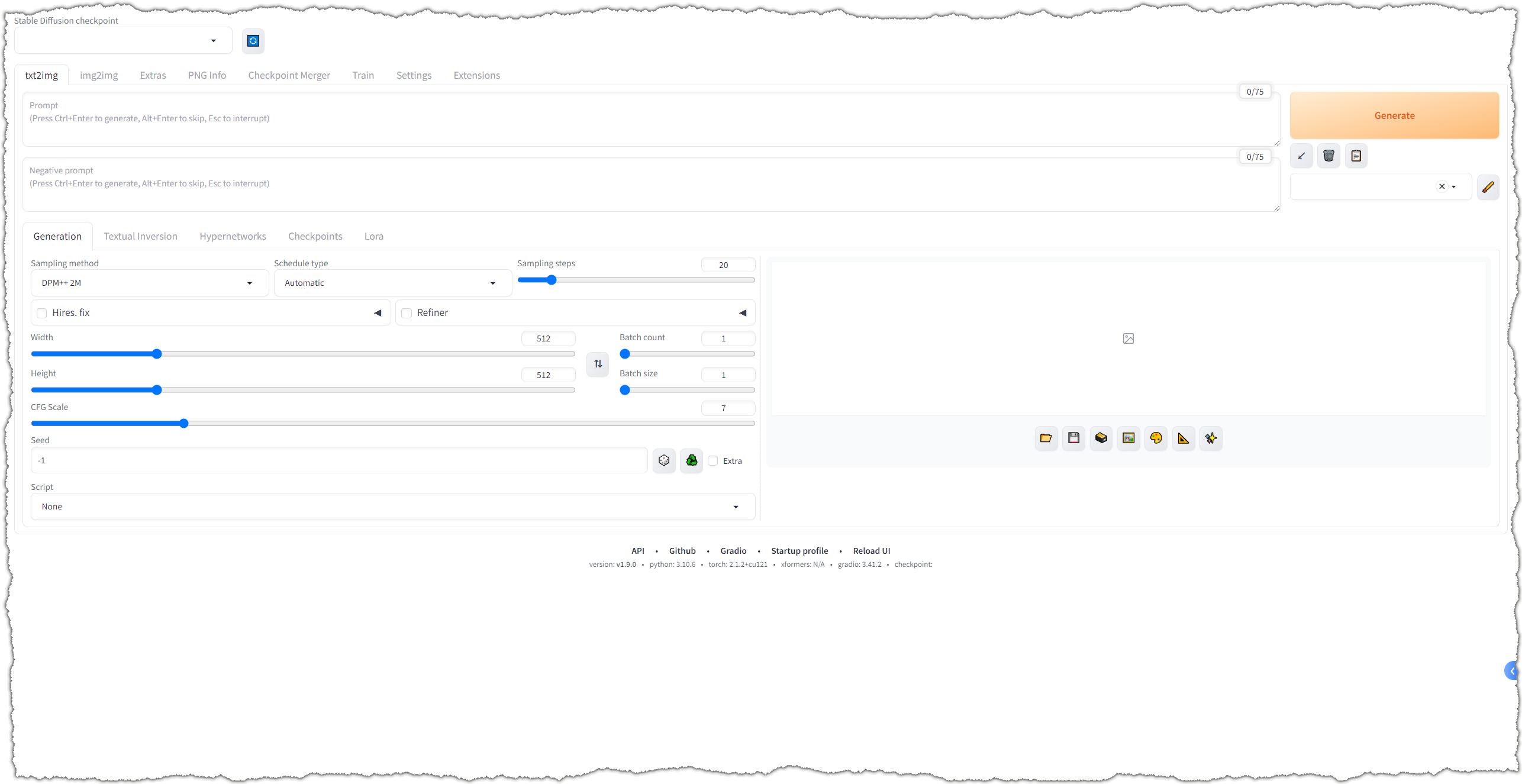
程序下载完成后,系统默认浏览器会自动访问本机地址:http://127.0.0.1:7860/,界面如下:
常见问题:下载所需文件的网站在海外,看本地的网络情况,可能需要开启魔法,具体请参考[🔗6.1准备工作/6.1.1魔法 ↗]章节。
4.参数
官方参数文档:🔗https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Command-Line-Arguments-and-Settings ↗
环境变量
| 名称 | 描述 |
|---|---|
| PYTHON | 设置 Python 可执行文件的自定义路径。例如,如果要使用特定的 Python 版本,可以将其设置为该版本的路径。 |
| VENV_DIR | 指定虚拟环境的路径。如果未设置,则会在根目录中创建名为 venv 的虚拟环境。 |
| COMMANDLINE_ARGS | 主程序的附加命令行参数。例如,可以使用此参数来指定要生成的图像的分辨率或样式。 |
| IGNORE_CMD_ARGS_ERRORS | 忽略命令行参数错误,不中断退出。如果设置为任何值,则即使遇到未知的命令行参数,程序也不会退出。 |
| REQS_FILE | 默认为 requirements_versions.txt,设置运行时安装具有依赖项文件的名称。此文件指定了运行 Stable Diffusion Web UI 所需的 Python 包。 |
| TORCH_COMMAND | 用于安装 PyTorch 的命令。如果未设置,则将使用默认的 PyTorch 安装命令。 |
| INDEX_URL | 相当于 --index-url 的参数。此参数指定了 pip 用于下载 Python 包的索引 URL。 |
| TRANSFORMERS_CACHE | Transformers 库下载并保存与 CLIP 模型相关的文件的路径。CLIP 模型用于将文本描述转换为图像。 |
| CUDA_VISIBLE_DEVICES | 如果系统上有多个 GPU,可以指定要使用的 GPU。例如,如果要使用第二个 GPU,可以将其设置为 1。 |
| SD_WEBUI_LOG_LEVEL | 设置日志记录的详细程度。支持任何有效的 Python 内置日志记录模块支持的日志记录级别。默认值为 INFO。 |
| SD_WEBUI_CACHE_FILE | 缓存文件的路径。如果未设置,则默认为根目录中的 cache.json。 |
| SD_WEBUI_RESTART | 由启动器脚本(如 webui.bat 或 webui.sh)设置的值,通知 WebUI 存在重启功能。 |
| SD_WEBUI_RESTARTING | 一个内部值,表示 WebUI 是否正在重新启动或重新加载,用于禁用某些操作,例如自动启动浏览器。 |
命令行参数
配置参数(CONFIGURATION)
| Argument Command | Value | Default | Description |
|---|---|---|---|
| -h, –help | None | False | 显示此帮助消息并退出。 |
| –exit | 安装后终止。 | ||
| –data-dir | DATA_DIR | / | 存储所有用户数据的基本路径。 |
| –config | CONFIG | configs/stable-diffusion/v1-inference.yaml | 构建模型的配置路径。 |
| –ckpt | CKPT | model.ckpt | Stable Diffusion模型的检查点路径;如果指定,此检查点将被添加到检查点列表并加载。 |
| –ckpt-dir | CKPT_DIR | None | Stable Diffusion检查点的目录路径。 |
| –no-download-sd-model | None | False | 即使没有找到模型,也不下载SD1.5模型。 |
| –do-not-download-clip | None | False | 即使检查点中不包含CLIP模型,也不下载CLIP模型。 |
| –vae-dir | VAE_PATH | None | 变分自动编码器模型的路径。 |
| –vae-path | VAE_PATH | None | 将被用作VAE的检查点;设置此参数。 |
| –gfpgan-dir | GFPGAN_DIR | GFPGAN/ | GFPGAN目录。 |
| –gfpgan-model | GFPGAN_MODEL | GFPGAN模型文件名。 | |
| –codeformer-models-path | CODEFORMER_MODELS_PATH | models/Codeformer/ | codeformer模型文件的目录路径。 |
| –gfpgan-models-path | GFPGAN_MODELS_PATH | models/GFPGAN | 包含GFPGAN模型文件的目录路径。 |
| –esrgan-models-path | ESRGAN_MODELS_PATH | models/ESRGAN | 包含ESRGAN模型文件的目录路径。 |
| –bsrgan-models-path | BSRGAN_MODELS_PATH | models/BSRGAN | 包含BSRGAN模型文件的目录路径。 |
| –realesrgan-models-path | REALESRGAN_MODELS_PATH | models/RealESRGAN | 包含RealESRGAN模型文件的目录路径。 |
| –scunet-models-path | SCUNET_MODELS_PATH | models/ScuNET | 包含ScuNET模型文件的目录路径。 |
| –swinir-models-path | SWINIR_MODELS_PATH | models/SwinIR | 包含SwinIR和SwinIR v2模型文件的目录路径。 |
| –ldsr-models-path | LDSR_MODELS_PATH | models/LDSR | 包含LDSR模型文件的目录路径。 |
| –lora-dir | LORA_DIR | models/Lora | 包含Lora网络的目录路径。 |
| –clip-models-path | CLIP_MODELS_PATH | None | 包含CLIP模型文件的目录路径。 |
| –embeddings-dir | EMBEDDINGS_DIR | embeddings/ | 文本倒置的Embeddings目录(默认: embeddings/)。 |
| –textual-inversion-templates-dir | TEXTUAL_INVERSION_TEMPLATES_DIR | textual_inversion_templates | 包含文本倒置模板的目录。 |
| –hypernetwork-dir | HYPERNETWORK_DIR | models/hypernetworks/ | hypernetwork目录。 |
| –localizations-dir | LOCALIZATIONS_DIR | localizations/ | 本地化目录。 |
| –styles-file | STYLES_FILE | styles.csv | 用于样式的文件名。 |
| –ui-config-file | UI_CONFIG_FILE | ui-config.json | 用于UI配置的文件名。 |
| –no-progressbar-hiding | None | False | 在gradio UI中不隐藏进度条(我们隐藏它是因为它会减慢浏览器中ML的速度,如果你有硬件加速)。 |
| –max-batch-count | MAX_BATCH_COUNT | 16 | UI的最大批处理数量值。 |
| –ui-settings-file | UI_SETTINGS_FILE | config.json | 用于UI设置的文件名。 |
| –allow-code | None | False | 允许从Web UI执行自定义脚本。 |
| –share | None | False | 对于 gradio,使用 share=true 并使 UI 可通过他们的网站访问。 |
| –listen | None | False | 以 0.0.0.0 作为服务器名称启动 gradio,允许响应网络请求。 |
| –port | PORT | 7860 | 使用指定的服务器端口启动 gradio,端口 < 1024 需要 root/admin 权限,如果可用则默认为 7860。 |
| –hide-ui-dir-config | None | False | 从 web UI 中隐藏目录配置。 |
| –freeze-settings | None | False | 禁用编辑设置。 |
| –enable-insecure-extension-access | None | False | 无视其他选项,启用扩展选项卡。 |
| –gradio-debug | None | False | 使用 –debug 选项启动 gradio。 |
| –gradio-auth | GRADIO_AUTH | None | 设置 gradio 身份验证,如 username:password; 或以逗号分隔多个,如 u1:p1,u2:p2,u3:p3。 |
| –gradio-auth-path | GRADIO_AUTH_PATH | None | 设置 gradio 身份验证文件路径,例如 /path/to/auth/file,格式与 –gradio-auth 相同。 |
| –disable-console-progressbars | None | False | 不在控制台输出进度条。 |
| –enable-console-prompts | None | False | 在使用 txt2img 和 img2img 生成时在控制台打印提示。 |
| –api | None | False | 启动带有 API 的 web UI。 |
| –api-auth | API_AUTH | None | 设置 API 身份验证,如 username:password; 或以逗号分隔多个,如 u1:p1,u2:p2,u3:p3。 |
| –api-log | None | False | 启用记录所有 API 请求。 |
| –nowebui | None | False | 仅启动 API,不启动 UI。 |
| –ui-debug-mode | None | False | 不加载模型以快速启动 UI。 |
| –device-id | DEVICE_ID | None | 选择要使用的默认 CUDA 设备 (在使用之前可能需要先运行 export CUDA_VISIBLE_DEVICES=0,1 等命令)。 |
| –administrator | None | False | 管理员权限。 |
| –cors-allow-origins | CORS_ALLOW_ORIGINS | None | 允许的 CORS 来源(以逗号分隔的列表形式)。 |
| –cors-allow-origins-regex | CORS_ALLOW_ORIGINS_REGEX | None | 允许的 CORS 来源(以单个正则表达式的形式)。 |
| –tls-keyfile | TLS_KEYFILE | None | 部分启用 TLS,需要 –tls-certfile 才能完全启用。 |
| –tls-certfile | TLS_CERTFILE | None | 部分启用 TLS,需要 –tls-keyfile 才能完全启用。 |
| –disable-tls-verify | None | False | 如果传递,则启用使用自签名证书。 |
| –server-name | SERVER_NAME | None | 设置服务器的主机名。 |
| –no-gradio-queue | None | False | 禁用 gradio 队列;导致 webpage 使用 http 请求而不是 websockets,这是早期版本的默认行为。 |
| –gradio-allowed-path | None | None | 将路径添加到 Gradio 的 allowed_paths;可以从中提供文件。 |
| –no-hashing | None | False | 禁用 SHA-256 校验和以帮助加载性能。 |
| –skip-version-check | None | False | 不检查 torch 和 xformers 的版本。 |
| –skip-python-version-check | None | False | 不检查 Python 的版本。 |
| –skip-torch-cuda-test | None | False | 不检查 CUDA 是否能正常工作。 |
| –skip-install | None | False | 跳过安装包。 |
| –loglevel | None | None | 日志级别: 例如 CRITICAL, ERROR, WARNING, INFO, DEBUG。 |
| –log-startup | None | False | 以参数形式启动时,详细记录启动过程。 |
| –api-server-stop | None | False | 启用通过 api 停止/重启/终止服务器。 |
| –timeout-keep-alive | int | 30 | 为 uvicorn 设置 timeout_keep_alive。 |
性能参数(PERFORMANCE)
| Argument Command | Value | Default | Description |
|---|---|---|---|
| –xformers | None | False | 启用 xformers 用于交叉注意力层。 |
| –force-enable-xformers | None | False | 无视检查代码的判断,强制启用 xformers 用于交叉注意力层;如果失败不会发出 bug 报告。 |
| –xformers-flash-attention | None | False | 启用带有 Flash Attention 的 xformers 以提高可重复性(仅支持 SD 2.x 或更高版本)。 |
| –opt-sdp-attention | None | False | 启用缩放点积交叉注意力层优化;需要 PyTorch 2+ |
| –opt-sdp-no-mem-attention | False | None | 启用缩放点积交叉注意力层优化,但不进行内存高效注意力,使图像生成过程确定性;需要 PyTorch 2+ |
| –opt-split-attention | None | False | 强制启用 Doggettx 的交叉注意力层优化。默认在支持 CUDA 的系统上启用。 |
| –opt-split-attention-invokeai | None | False | 强制启用 InvokeAI 的交叉注意力层优化。默认在 CUDA 不可用时启用。 |
| –opt-split-attention-v1 | None | False | 启用旧版本的分割注意力优化,该优化不会消耗所有可用的 VRAM。 |
| –opt-sub-quad-attention | None | False | 启用内存高效的子二次交叉注意力层优化。 |
| –sub-quad-q-chunk-size | SUB_QUAD_Q_CHUNK_SIZE | 1024 | 用于子二次交叉注意力层优化的查询分块大小。 |
| –sub-quad-kv-chunk-size | SUB_QUAD_KV_CHUNK_SIZE | None | 用于子二次交叉注意力层优化的 KV 分块大小。 |
| –sub-quad-chunk-threshold | SUB_QUAD_CHUNK_THRESHOLD | None | 子二次交叉注意力层优化使用分块的 VRAM 阈值百分比。 |
| –opt-channelslast | None | False | 启用 4d 张量的替代布局,可能会使 Nvidia 张量核心卡(16xx 及更高)的推理速度更快。 |
| –disable-opt-split-attention | None | False | 强制禁用交叉注意力层优化。 |
| –disable-nan-check | None | False | 不检查生成的图像/潜在空间是否含有 nan;在 Cl 中运行无检查点时有用。 |
| –use-cpu | {all, sd, interrogate, gfpgan, bsrgan, esrgan, scunet, codeformer} | None | 使用 CPU 作为指定模块的 torch 设备。 |
| –no-half | None | False | 不将模型切换为 16 位浮点数。 |
| –precision | {full,autocast} | autocast | 使用此精度进行评估。 |
| –no-half-vae | None | False | 不将 VAE 模型切换为 16 位浮点数。 |
| –upcast-sampling | None | False | Upcast 采样。与 –no-half 无影响。通常会产生与 –no-half 相似的结果,但性能更好,内存使用更少。 |
| –medvram | None | False | 启用 Stable Diffusion 模型优化,以牺牲一些性能来节省 VRAM 使用。 |
| –medvram-sdxl | None | False | 仅为 SDXL 模型启用 –medvram 优化。 |
| –lowvram | None | False | 启用 Stable Diffusion 模型优化,以大幅牺牲速度来节省大量 VRAM 使用。 |
| –lowram | None | False | 将 Stable Diffusion 检查点权重加载到 VRAM 而非 RAM。 |
| –disable-model-loading-ram-optimization | None | False | 禁用在加载模型时减少 RAM 使用的优化。 |
功能参数(FEATURES)
| Argument Command | Value | Default | Description |
|---|---|---|---|
| –autolaunch | None | False | 启动时在系统的默认浏览器中打开 web UI URL。 |
| –theme | None | Unset | 使用指定主题(light 或 dark)打开 web UI。如果未指定,使用默认浏览器主题。 |
| –use-textbox-seed | None | False | 在 UI 中使用文本框输入种子(无上下箭头,但可输入较长的种子)。 |
| –disable-safe-unpickle | None | False | 禁用检查 PyTorch 模型中的恶意代码。 |
| –ngrok | NGROK | None | ngrok 认证令牌,替代 gradio –share。 |
| –ngrok-region | NGROK_REGION | us | ngrok 应该启动的区域。 |
| –ngrok-options | NGROK_OPTIONS | None | 以 JSON 格式传递给 ngrok 的选项,例如:{“authtoken_from_env”:true,”basic_auth”:”user:password”,”oauth_provider”:”google”,”oauth_allow_emails”:”user@asdf.com“} |
| –update-check | None | None | 在启动时,通知你的 web UI 版本(commit)是否与当前主分支同步。 |
| –update-all-extensions | None | None | 在启动时,为你已安装的所有扩展程序拉取最新更新。 |
| –reinstall-xformers | None | False | 强制重新安装 xformers。升级时很有用 – 但升级后请移除,否则会反复重新安装 xformers。 |
| –reinstall-torch | None | False | 强制重新安装 torch。升级时很有用 – 但升级后请移除,否则会反复重新安装 torch。 |
| –tests | TESTS | False | 运行测试以验证 web UI 功能,详情请参阅 wiki 主题。 |
| –no-tests | None | False | 即使指定了 –tests 选项,也不运行测试。 |
| –dump-sysinfo | None | False | launch.py 参数:将有限的 sysinfo 文件(不包含关于扩展、选项的信息)转储到磁盘并退出。 |
| –disable-all-extensions | None | False | 禁用运行所有非内置扩展程序。 |
| –disable-extra-extensions | None | False | 禁用运行所有扩展程序。 |
废弃的选项(DEFUNCT OPTIONS)
| Argument Command | Value | Default | Description |
|---|---|---|---|
| –show-negative-prompt | None | False | 不再有任何效果。 |
| –deepdanbooru | None | False | 不再有任何效果。 |
| –unload-gfpgan | None | False | 不再有任何效果。 |
| –gradio-img2img-tool | GRADIO_IMG2IMG_TOOL | None | 不再有任何效果。 |
| –gradio-inpaint-tool | GRADIO_INPAINT_TOOL | None | 不再有任何效果。 |
| –gradio-queue | None | False | 不再有任何效果。 |
| –add-stop-route | None | False | 不再有任何效果。 |
| –always-batch-cond-uncond | None | False | 不再有任何效果,已移入UI界面,在“设置”>“优化”下。 |
介绍常用的几个参数,用记事本打开文件:\webui\webui-user.bat,如图:
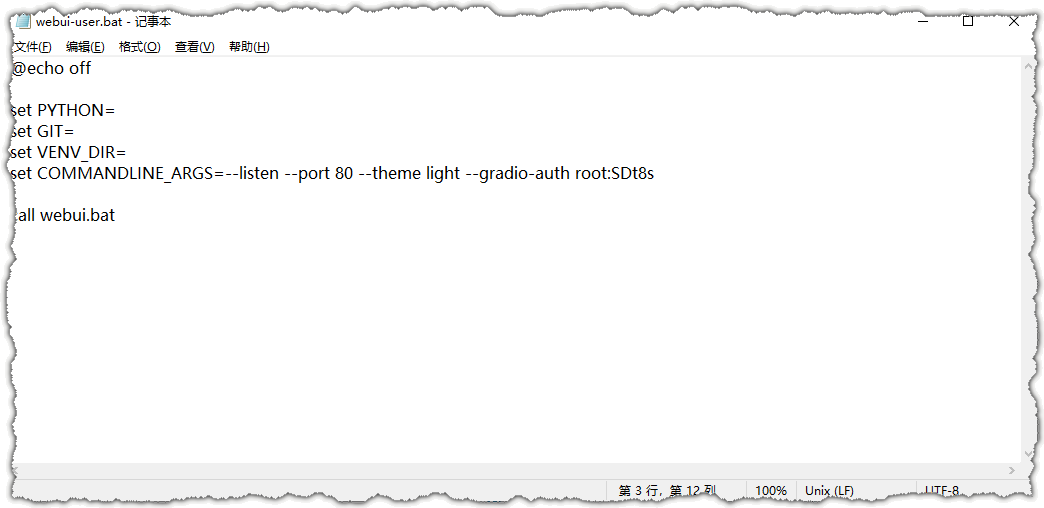
修改set COMMANDLINE_ARGS=这一行,参数说明:
4.1 –listen
使用0.0.0.0作为服务器名称启动Gradio(服务用 Python的Gradio库实现),可以通过服务器的所有IP访问,如果服务器有公网IP,就可以在外网访问了;若端口为 80,本地访问:http://127.0.0.1/
4.2 –port 80
使用80端口启动Gradio
4.3 –gradio-auth root:SDt8
设置Gradio身份验证,用户名为root,密码为SDt8s
4.4 –theme light
在WebUI中使用明暗主题,参数值:light/dark
light:
dark:
5.模型
模型一般在 C 站(下文有介绍)下载即可,但是因为 C 站在海外,下载速度比较慢,需要魔法;因为工作需要,我在百度网盘放了一些模型,可以通过百度网盘下载( 下载地址:https://www.buzhou.ai/category/model/),如果百度网盘没有需要的模型,可在评论区留言,发送下载链接或者C站链接,我会第一时间下载并回复;
6.提示词
参照C站的一个图片的提示词生成的图片:🔗https://civitai.com/images/10896202 ↗
提示词有几种生成方式:
1.手动编写;需要对使用的大模型以及图象的生成规则有非常全面的了解,精通英文,还需要有一定的词汇量储备;
2.通过大模型生成;通过大语言模型(如 ChatGPT、Claude、Gemini等)的角色设定和提示词工程,也可以输出高质量的文生图提示词;
3.用提示词工具生成;
7.工具
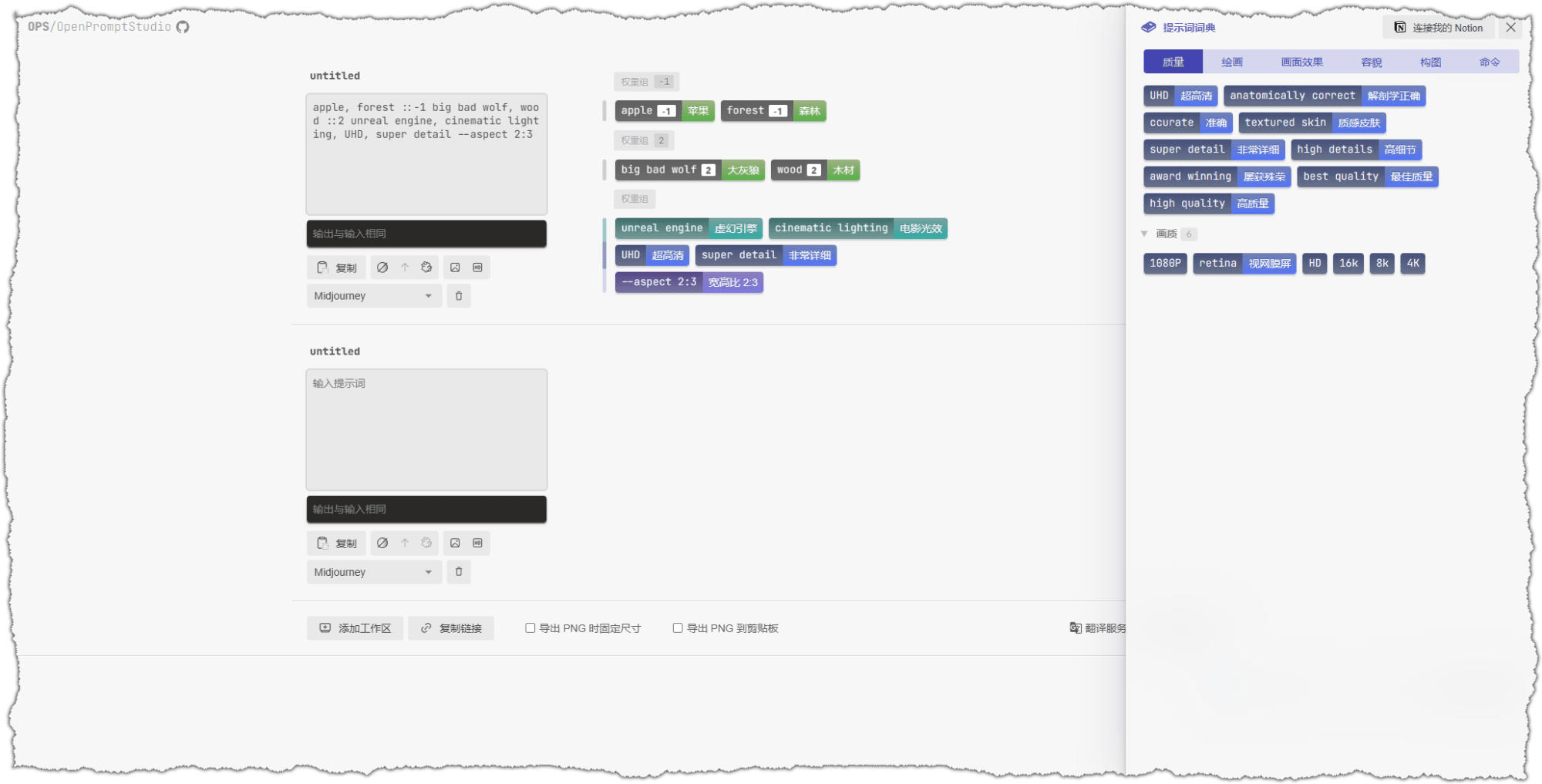
提示词可视化编辑器:🔗https://label.tool.wapple.cn/apps/ops/ ↗
支持6.4Stable Diffusion和6.5MidJourney,输入中文,自动翻译成英文,预设质量、绘画、画面效果、容貌、构图、命令等方面的提成词;
大模型提示词指令:🔗https://prompt.vercel.wapple.cn/ ↗


8.界面主题
LobeHub官方库地址:🔗https://github.com/lobehub/sd-webui-lobe-theme ↗
百度网盘地址:🔗https://pan.baidu.com/s/1LKoA13HXJwQ4q5jbo0OiYA?pwd=42bf ↗
下载主题文件,解压缩到\webui\extensions,如图:

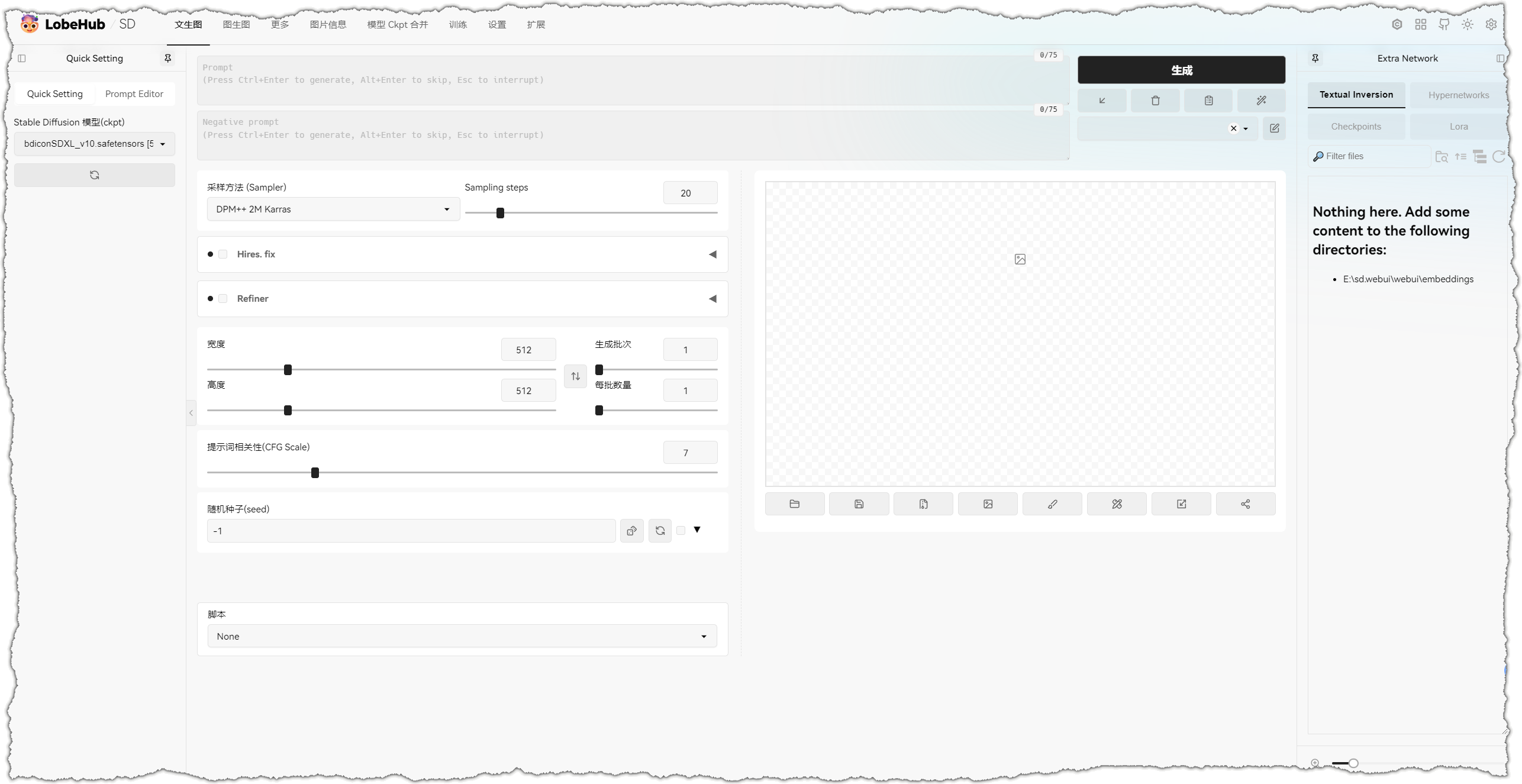
重新运行run.bat,会自动加载主题,主题预览:
9.C站
🔗https://civitai.com/ ↗ 俗称C站,主要是下载各种模型和学习如何写出优质的提示词。
Civitai.com 是一个专注于 Stable Diffusion 模型和相关创作工具的开源社区平台。它为广大艺术家、开发者和爱好者提供了一个交流和分享创意的理想场所。
该平台的主要功能包括:
1. 模型共享:Civitai 汇集了来自全球的 Stable Diffusion 模型和训练权重,用户可以免费下载和使用这些资源进行创作。这些模型涵盖各种风格和应用场景,为用户的创作提供了广阔的可能性。
2. 提示词交流:用户可以在平台上分享自己编写的高质量提示词,供其他创作者参考和使用。同时,也可以探讨提示词的编写技巧,互相学习和进步。
3. 创作展示:Civitai 设有专门的作品展示区,用户可以在这里分享自己使用 Stable Diffusion 生成的创作成果,并获得来自社区的反馈和互动。这有助于激发创意灵感,推动整个创作生态的发展。
4. 教程分享:平台上也有大量优质的教程资源,涵盖 Stable Diffusion 的安装、使用、优化等方方面面。新手用户可以通过这些教程快速入门,而有经验的用户也能从中学习到新的技巧和窍门。
5. 社区交流:Civitai 拥有活跃的社区论坛,用户可以在这里就感兴趣的话题进行讨论,交流自己的心得体会。这有助于增进用户之间的联系,促进知识和创意的传播。
无论您是初学者还是资深从业者,都可以在这里获得所需的模型、提示词、教程等支持,从而进一步提高自己的 Stable Diffusion 创作水平。
